
March 2026 update
Free-threaded Python support for FastAPI, the ty type checker, analysing loss curves, autoresearch and LLM-readable documentation in skills.md

March has been another busy month on the OSS front. These are the main topics I’ll cover in this monthly update:
Getting FastAPI ready for free-threaded Python
Introducing Astral’s ty into FastAPI’s lint checker
Analysing loss curves to triage nanochat user contributions
Welcoming nanochat’s little brother ‘autoresearch’
Publishing skills files to help LLMs write the best code for frameworks you maintain
Free-threaded Python
Since v3.13, CPython supports building Python in a “free threaded” model, which means thath the GIL (global interpreter lock) is disabled. This then paves the way for more efficient execution of Python programs by utilizing all available CPU cores in parallel threads. The Python versions that support free-threading are denoted with a “t” at the end, so e.g. 3.13t and 3.14t.
There’s been quite a lot of work done in the ecosystem to start supporting these free-threaded Python versions, which isn’t always trivial. Nathan Goldbaum and other colleagues at Quansight Labs have been working hard to get core packages such as NumPy and scipy to fully support a nogil build of Python. About half a year ago, we started looking into this for FastAPI as well (cf. PR 13946), but quickly ran into dependencies that weren’t compatible yet: httptools, pydantic, bcrypt and orjson to name a few. The beauty of open-source: I pinged Nathan (out of the blue) to help assess the situation for FastAPI and not only did he show up in the PR thread with some pointers and advice, he also went on to help httptools fix their CI and get ready for free-threaded support.
While the ecosystem was working on this, we put it on the back burner for FastAPI for a few months, until I took it back up this month in PR 15149. This time even without asking, Nathan showed up with helpful advice and helped us get fastar ready for nogil <3.
The final steps then to get FastAPI ready for Python 3.14t, was to remove orjson and ujson as standard test dependencies, which was possible since FastAPI’s BDFL Sebastián Ramírez (commonly known as Tiangolo) had deprecated ORJSONResponse and UJSONResponse in favour of using JSON responses that can be serialized with Pydantic (cf. PR 14962).
I’m pretty happy with how this has worked out, and it was super nice to interact with the folks from Quansight Labs. With all of the LLM-slop PRs, reviews and conversations that we’re dealing with on GitHub lately, it’s great to interact with actual people who are just super helpful and genuinely care about the ecosystem. Thanks a bunch, Nathan & team! The 3.14t PR isn’t merged yet - it’s waiting for a final review by Sebastián - but you can expect free-threaded support in FastAPI sometime soon!
ty is for types
Not only has Astral taken the Python world by storm with their fast package manager uv, and their linter ruff, but now they’ve also published a new type checker called ty. Like its siblings, ofcourse, it’s implemented in Rust.
Over at FastAPI, we think types are quite a big deal, and up until now we’ve been using mypy for our precommit linting needs. Mypy is pretty good and stable, but still suffers from some false positives (notifications that aren’t errors) and false negatives (errors that aren’t reported). Running a second tool in parallel might not be a bad idea!
When we posted about this on LinkedIn, there were some comments about ty not being ready for production yet. But it’s important to realize that ty isn’t being run in production: it’s a precommit check for a production-ready codebase, and all of its warnings and errors are manually reviewed by us, the maintainers of said codebase, before pushing any code to production. It’s really just a tool to help us find potential issues in the code base, just like mypy is.
So, I set out to add ty to the precommit steps in all of fastapi’s OS libraries: not only FastAPI itself, but also Typer, Asyncer, SQLModel, annotated-doc, markdown-include-variantes, etc etc. You get the idea. I started with Typer, as it’s my favourite OS repo to work on and a good guinea pig as FastAPI’s little sibling. Here, I noticed that ty sometimes doesn’t infer the correct type, and requires additional cast and/or assert statements to help it see the correct type. Alternatively, you can just add an ignore statement to this line that will suppress ty’s warning/error. We opted for the latter, though this requires some care: don’t just put “type: ignore” when you’re running mypy in parallel. Because in those cases where mypy doesn’t see an issue, it will in fact complain that the ignore statement is unnecessary. You can put “ty: ignore” instead (mind the two missing letters), so that it become a ty-specific ignore statement and won’t influence mypy in any way.
There were a few spots in Typer’s code base where we were using a try-catch instead of an explicit if-else to check for existence of certain attributes. ty rightfully called this out, and it’s one of those small improvements we were able to make by integrating ty into the precommit check.
In Asyncer, there was a class definition that mypy had issues with, and we had previously decided to annotated with “type: ignore” to suppress mypy’s warning. Now ty comes along, and decides there is actually no issue with this line. For ty versions 0.0.24 and before, this would mean that you’d have to add a second ignore statement and the line becomes something like this:
class X(Y): # type: ignore # ty: ignore[unused-ignore-comment]
Which is not super satisfying. However from ty 0.0.25 onwards, ty can actually parse the error codes within a “type:ignore” statement, something it couldn’t before (cf. PR 24096). This means that if you put the exact mypy code within brackets, ty will parse it, decide it’s not one of its known codes, and ignore it. So when updating ty to 0.0.25 or above, the ugly line quoted above becomes something like
class X(Y): # type: ignore[valid-type]
Which is much better. In general, if you prefer to run ty in parallel with any other type checker, I’d definitely recommend using 0.0.25 and above.
Continuing with our other repos, many actually required zero code updates after adding ty to the precommit step, which is nice (e.g. fastapi-new, fastapi-cli, annotated-doc, markdown-include-variants). However, when running ty on FastAPI’s code base for the first time, no less than 150 issues popped up. Some of these were actually pretty useful, for instance pointing to Pydantic v2 deprecations that FastAPI should have addressed earlier but didn’t because our CI tests for the lower ranges of our dependencies were broken (this is the type of rabbit hole you often find yourself in when open-source-maintaining). So we fixed the CI first (with some helpful digging by Yurii Motov), and then addressed the deprecations properly. This is a clear case where ty helped us identify issues that hadn’t been reported by mypy. But the same is also true in reverse: mypy sometimes finds issues that ty doesn’t. So for now we’re happy running both in parallel. And yes - thanks for asking - I did manage to resolve all 150 issues, with help from Yurii who gave super detailed and constructive feedback on the PR. Team work makes the dream work ;-)
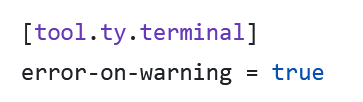
Eventually we also decided to mark ty warnings as errors that would fail the CI. This is easily achieved by setting this in your pyproject.toml:
Loss curves going down, down, down
As you may remember from previous posts, I’ve been involved in the maintenance of Andrej Karpathy’s nanochat repo, which provides all code for training and fine-tuning an LLM. In February, Andrej had set up a leaderboard to help incentivize improvements to the pretraining stage of nanochat. Comparing performance using the CORE score, the aim is to get to GPT2-level capabilities in as little as time as possible, measured on a 8xH100. Ideally, also val_bpb should go down, which is a sort of normalized, vocab-size-invariant loss score.
So one thing I’ve been doing to help assess user contributions that aim to improve nanochat’s pretraining code, is to do a quick sanity check on a (single) A100 instance I have access to. Using W&B, which is awesome for creating graphs you can spend all day looking at, I can then easily plot & compare different PR contributions:
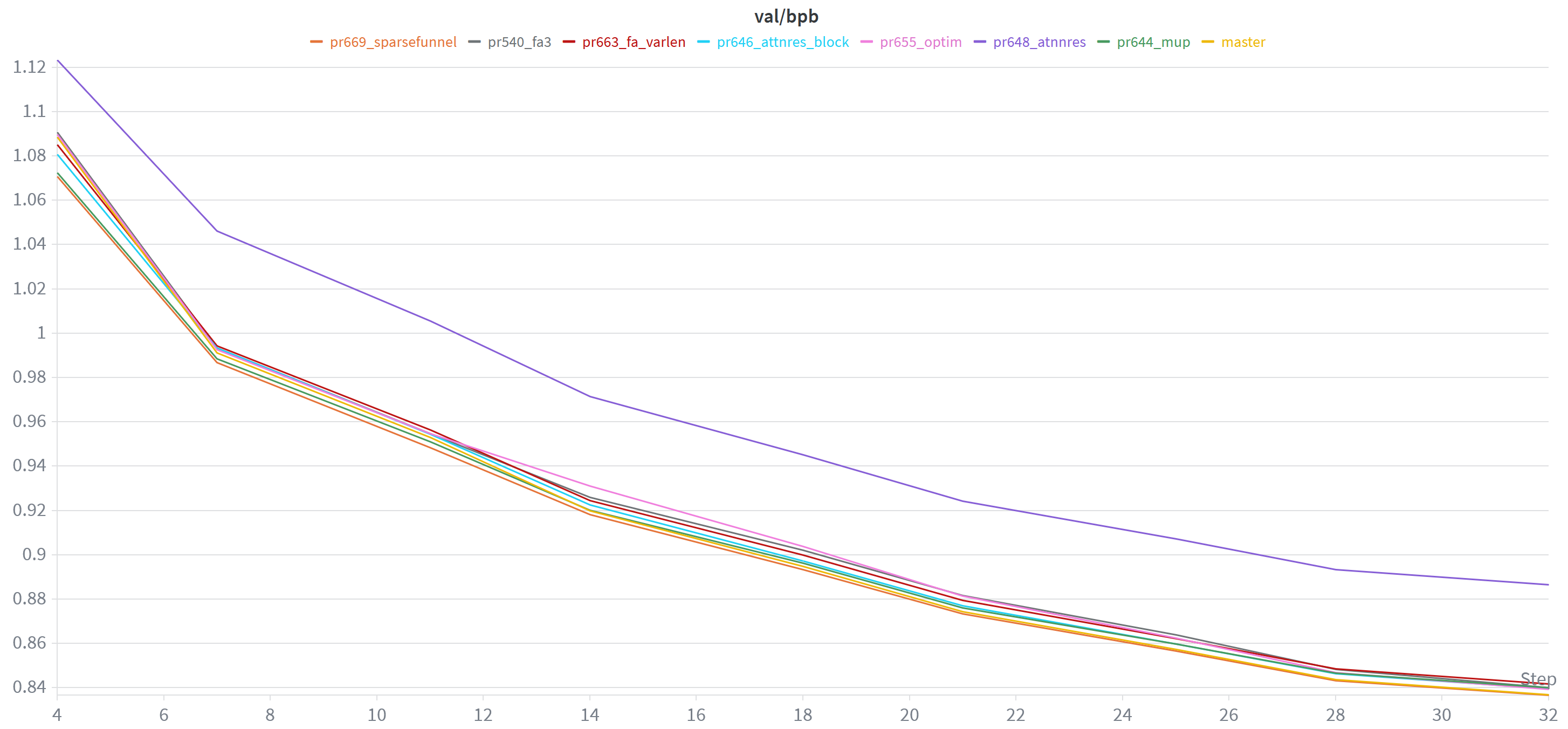
These are all d14 runs on an A100, and in terms of val_bpb, master still comes out on top at the end.
There’s many other interesting plots to look at, and all of these graphs are created automatically for you when you run the nanochat training scripts and are logged into W&B. For instance, it’s also really useful to check memory usage or disk utilization stats:
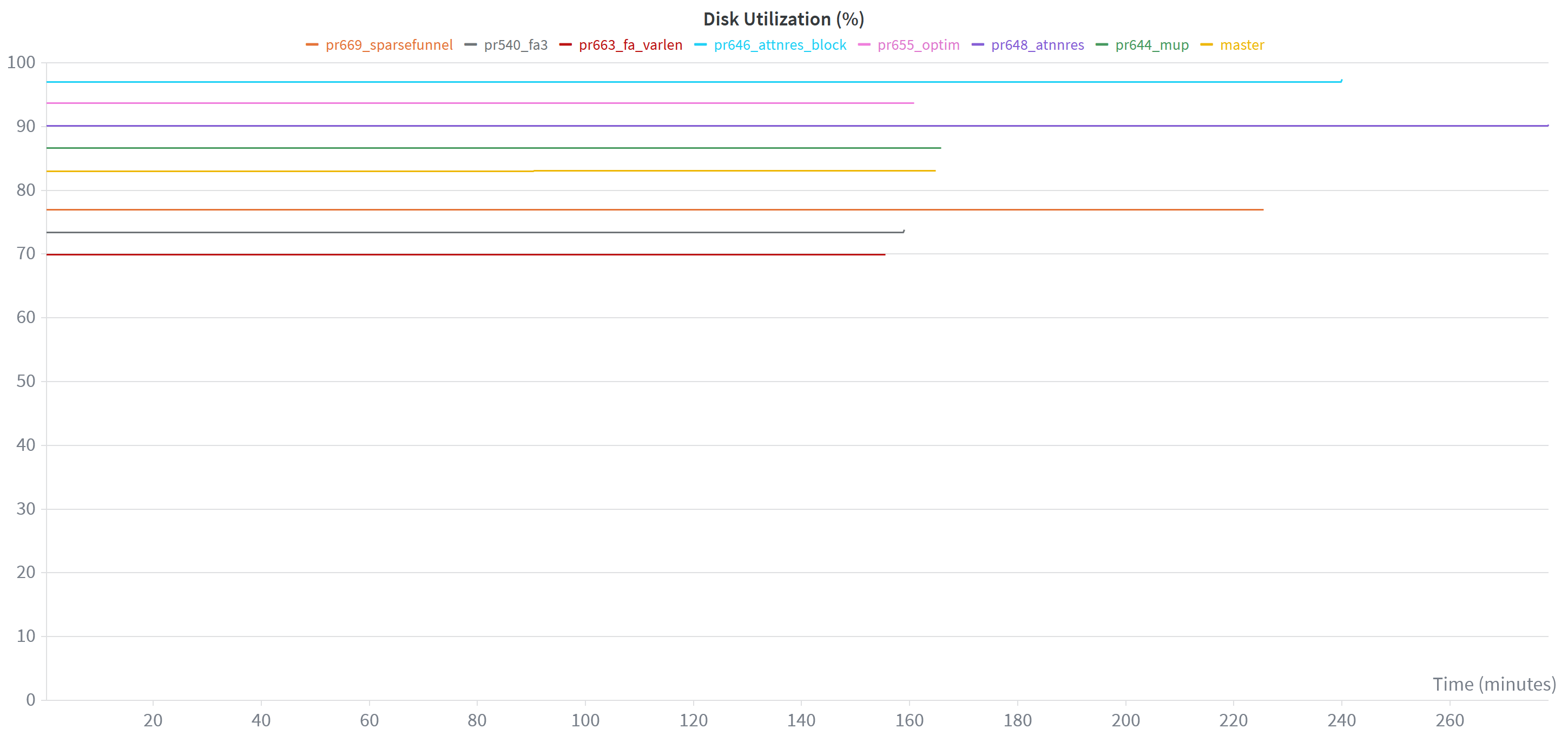
These plots are also useful to monitor your training run after having made code adjustements: you’ll typically be able to spot it relatively quickly if something is going fundamentally wrong with the loss profile. Then you don’t have to wait until the training run ends to go back in and correct things, saving you some valuable cloud credits…
Autoresearch: fine-tuning LLMs with LLMs
Meanwhile, Andrej himself was also experimenting with ways to further improve the pretraining step in nanochat, and push the limits of the leaderboard further. Eventually he decided to outsource his LLM engineering research to … an LLM. I’ve written a bit more about this, including an experiment with multiple agents riffing off eachother’s contributions in this post about autoresearch / autolab:

Publishing skills files for your repo
Who better to explain to agents how to write code for a certain framework, than the maintainers of said framework? This is actually a pretty cool exercise to do, a bit like writing documentation but for LLMs, not for humans. Sebastián had pioneered this idea in FastAPI, and I’ve written a similar one for Typer. What I find particularly promising with this approach is that you can tell LLMs how to navigate recent deprecations or breaking changes in your framework. You can show it best practices and even explain why, so in turn the LLM can review or write code for its human and explain the thought processes behind the change. Would love to get some feedback from the community whether it’s been helpful to them and how!
-Sofie